Le Contenu Dupliqué représente un contenu, ou une portion de contenu qui est repris à l’identique d’un autre site internet ou d’une autre page d’un même site internet.
Avoir une grosse quantité de contenus dupliqués peut avoir des répercussions négatives sur le classement de vos pages.
Google ne se limite pas à l’identification au contenu recopié mot pour mot, il est également capable d’interpréter des contenus trop similaires.
Sommaire
Qu’est-ce que le Contenu Dupliqué ?
En SEO, on parle régulièrement de contenu dupliqué.
C’est une thématique importante à laquelle il faut être attentif.
Je l’ai déjà dit dans l’introduction, mais voici une autre définition du contenu dupliqué : Il s’agit de bloc de contenus identiques ou très similaires qui se retrouvent sur des URLs distinctes.
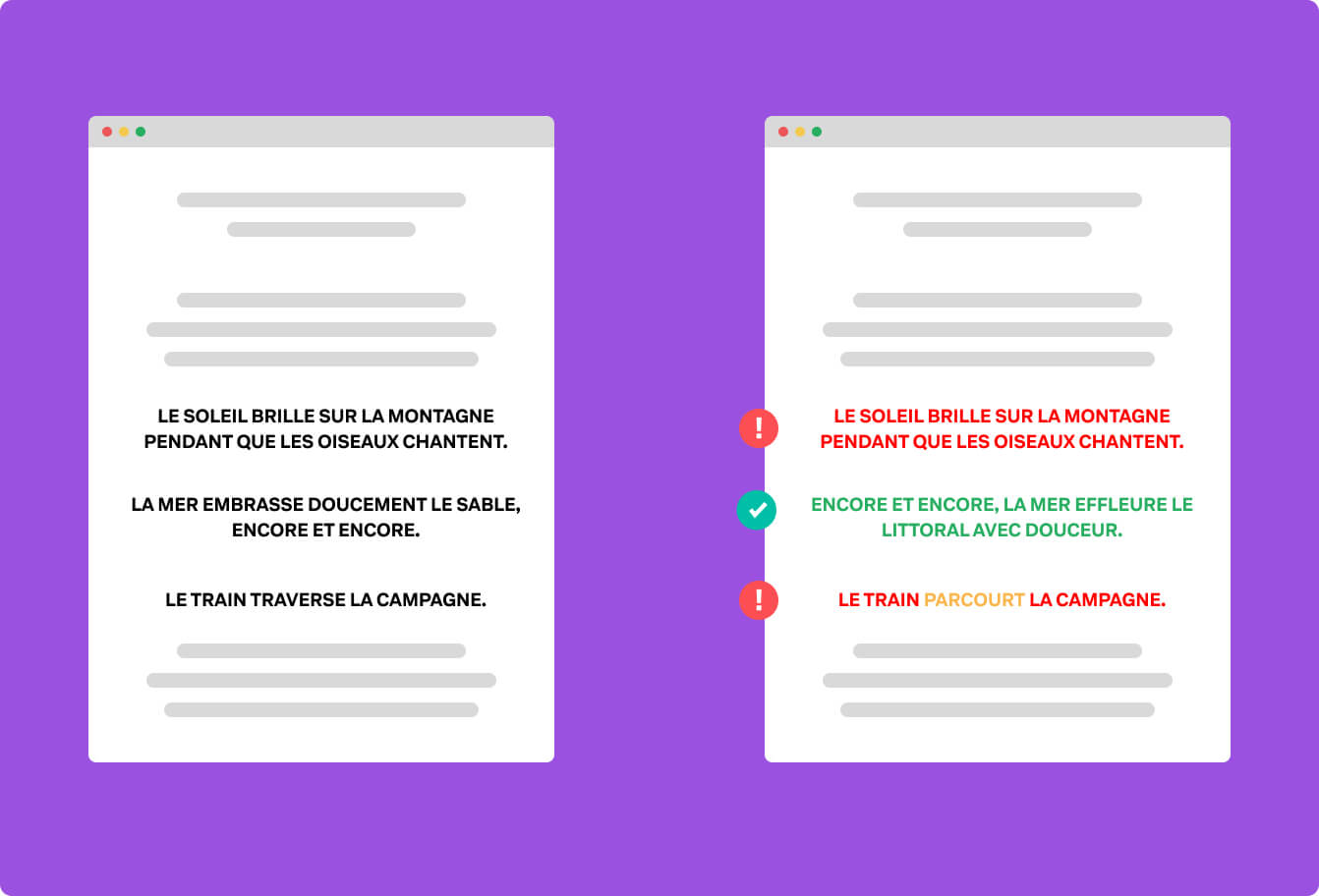
Vous l’aurez compris, qu’il s’agisse de votre contenu répliqué sur plusieurs pages, ou qu’il s’agisse de plagiat du contenu d’un autre site, les règles relatives au contenu dupliqué s’appliquent.
De même, changer quelques mots dans les phrases ne vous fera pas passer au travers des algorithmes de détections.
J’en ai déjà parlé lorsque j’abordais le fonctionnement de Googlebot sur la découverte et l’indexation des contenus. Google recherche des contenus très qualitatifs, et surtout, uniques.
Moins votre contenu sera unique, moins votre page sera appréciée.
Mais alors, je ne peux pas m’inspirer du contenu des autres ? Ou écrire les mêmes sujets qu’eux ?
Bien sûr, tout le monde s’inspire des autres créateurs de contenus. Par exemple cet article est inspiré de celui de Search Engine Island.
Et ce n’est pas grave qu’il le soit, tout simplement parce que j’écris ma propre pensée sur le sujet, avec ma propre manière de dire les choses.
Mon contenu est significativement différent du reste des articles sur le Contenu Dupliqué qu’on peut trouver sur Google, et c’est ça qui compte.
Significativement, c’est le mot important.
Les causes de contenu dupliqué
Au-delà du plagiat pur et dur, il existe plein de causes à l’existence de contenu dupliqué.
Je suis d’ailleurs sûr que la majorité d’entre vous ont du contenu dupliqué sur leurs sites, sans même le savoir.
C’est particulièrement courant sur les sites WordPress dont l’équipe de développeurs semble passer plus de temps à créer des pages invisibles pleines de contenus dupliqués qu’à développer des features utiles.
(Elle est gratuite celle-ci 🫡)
Voici les principales causes de contenus dupliqués :
- Votre serveur web n’effectue pas de redirection automatique de vos URL en HTTP vers celles en HTTPS.
- Votre serveur web n’effectue pas de redirection automatique de vos URL en
http://exemple.comvers celles enhttps://www.exemple.com(ou inversement) - Votre serveur web n’effectue pas de redirection automatique lorsqu’un
/est manquant à la fin d’une URL :http://exemple.com->http://exemple.com/ - Vous n’avez pas d’URL Canoniques sur les pages qui implémentent des query strings (ou paramètres d’URL). Par exemple :
https://www.exemple.com/blog/&argument=blablabladevrait avoir comme URL canoniquehttps://www.exemple.com/blog/. - Votre site internet implémente la pagination par routes (
/blog/page/1,/blog/page/2, etc.) et ces pages n’indiquent pas la racine comme URL canonique (/blog/). - Vous avez des pages qui listent des éléments qui se retrouvent également sur d’autres pages. Par exemple, dans un blog, vous listez des liens vers des articles qui peuvent se retrouver à la fois dans
/blog/et dans/blog/categorie-de-l'article/(ou même sur la page d’accueil, par exemple c’est le cas sur notre site). - Une mauvaise configuration d’un site international qui pourrait renvoyer la version de la langue d’origine lorsque la traduction est manquante, plutôt que de faire une redirection.
- Les versions alternatives de vos pages. (AMP, ou les pages avec les extensions de language comme
*.phpou*.htmlou *.htmpour les plus communes)
Vous l’aurez sans doute compris, mais toutes les catégories de contenu dupliqué ne posent pas problème.
D’ailleurs, dans certains cas, vous pouvez totalement vous en moquer. (l’exemple des previews d’article de blog par exemple).
Dans d’autres cas, il faudra vous en préoccuper (et pas toujours pour les mêmes raisons).
Les myths sur le Contenu Dupliqué
Il n’est pas rare d’entendre dire que le contenu dupliqué peut causer des pénalités de la part des moteurs de recherche.
C’est absolument faux.
Si c’était le cas, il serait impossible d’atteindre des résultats convenables avec WordPress qui prend un malin plaisir à éparpiller du contenu dupliqué absolument PARTOUT (par défaut).
(Bam, celle-ci aussi c’est gratuit)
Google ne pénalise pas les sites qui ont du contenu dupliqué (en dehors des cas dans lesquels le site recherche à manipuler les résultats de recherche (plagiat, Spun Content, etc.) où effectuer des actions malveillantes).
Et c’est bien normal, il y a plein de raison pour laquelle retrouver du contenu similaire sur plusieurs pages distinctes de votre site est une bonne chose pour les utilisateurs.
Séparer vos articles de blog en plusieurs pages permet de raccourcir le temps de chargement de votre page blog.
De même, proposer des articles en relation, à la fin d’un article, est un bon moyen d’engager vos utilisateurs vers d’autres contenus intéressants.
Google détermine la page « source » pour un contenu dupliqué en appliquant des filtres. Ces filtres permettent de retirer les pages avec du contenu dupliqué lorsqu’il affiche une SERP.
Pour déterminer la page source, il utilise divers signaux (dont les backlinks).
Intervention manuelle
Il peut arriver qu’un site vole votre contenu et ne soit pas pénalisé pour autant. C’est assez rare, mais ça peut arriver.
Dans ce cas, il vous est permis de faire des réclamations manuelles afin qu’un examen manuel soit réalisé.
C’est bien joli tout ça, mais comment on fait pour trouver les sites qui volent notre contenu ?
D’expérience, c’est assez facile parce que ces sites ne prennent même pas la peine de modifier les liens présents dans le contenu.
Ainsi, si votre maillage interne est fait, vous devriez recevoir des backlinks de sites frauduleux.
Bien entendu, vous ne voulez PAS de ces backlinks, et vous devrez les désavouer rapidement dans la search console.
Vous pourrez également en profiter pour les dénoncer aux moteurs de recherche.
Honnêtement le vol de contenu est une tare et c’est assez long et pénible de lutter contre. Heureusement Google est assez performant pour les identifier automatiquement et vous préserver.
Les vrais impacts sur le SEO
Bien entendu, il existe des impacts pour le SEO.
Depuis tout à l’heure je pars du principe que vous créez des contenus uniques et de qualité, et, dans ce cas, vous ne risquez pas grand-chose.
Cependant, si vous réutilisez du contenu provenant d’autres sites internets (images, blocs de textes, etc.) tel qu’ils sont ailleurs dans l’index, alors Google mettra une moindre priorité sur votre page dans le classement.
Et c’est tout à fait compréhensible.
Google veut du contenu unique pour renouveler ses réponses aux internautes. N’espérez pas surclasser des résultats existant en recopiant leur contenu.
Ça ne veut pas dire que votre site sera pénalisé. Ça veut dire que vos pages n’auront pas de bons résultats.
Il est également possible que vos pages ne soient pas indéxées du tout. C’est assez rare et ça concerne plutôt les sites internet avec beaucoup de pages.
En fait, le contenu dupliqué consomme le Crawl Budget. Cette surconsommation peut conduire à des pages non indexées parce que Google ne sait pas quelle version de votre page choisir.
Ça peut également être parce que votre budget est dépassé.
Il vous faudra donc être particulièrement attentif à ces problématiques.
Contenir le Contenu Dupliqué
On vient de le voir, l’impact du Contenu Dupliqué n’est pas si catastrophique qu’on peut le lire sur le net.
Cela dit, ça peut poser quelques problèmes, qui relèvent plus de l’optimisation certes, mais des problèmes quand même.
Dans cette section, nous allons voir comment solutionner ces problèmes.
Supprimer le contenu dupliqué inutile
En premier lieu, supprimez les duplicatas qui n’ont aucun intérêt.
Si par exemple votre site internet affiche vos produits à la fois sur l’URL /produits/produit-1 et sur /produits/categorie-a/produit-1/, vous avez un problème à résoudre.
Dans ce cas, vous pourriez solutionner le problème en supprimant une des routes dans le code, ou en créant une règle de redirection 301. (Si vous le pouvez, supprimer la route.)
De même, il est fort probable que votre site gère la pagination de différentes façons, et vous propose les mêmes pages sur /blog/2/ et sur /blog/page/2/ ainsi que sur /blog?page=2.
Au hasard, WordPress vous propose cela par défaut.
(Oui, encore lui. Mais promis, on ne le déteste plus une fois qu’il est bien configuré.)
Vous n’avez pas besoin d’avoir 42 manières de faire la même chose.
Choisissez la manière de faire que vous préférez, et virez tout le reste. Nous par exemple, on a décidé de rester sur /blog/2/, toutes les autres requêtes de paginations redirigent vers une 404.
Le cas spécifique de la pagination
Même si vous n’avez plus qu’un format pour gérer votre pagination, elle propose toujours du contenu dupliqué.
Pour limiter l’impact de ces pages, vous devez mettre en place deux choses :
- Mettre en place l’URL canonique vers la page racine, par exemple
/blog/ - Mettre en place des balises
<link rel="prev" ... />et<link rel="next" ... />
Dans notre exemple du blog, vos pages ressembleraient à ça :
<html>
<head>
<!-- votre entête classique... -->
<title>Page 3 du Blog !</title>
<link rel="canonical" href="https://www.exemple.com/blog/">
<link rel="prev" href="https://www.exemple.com/blog/2/" />
<link rel="next" href="https://www.exemple.com/blog/4/" />
</head>
<body>
<!-- Votre page. -->
</body>
</html>Ainsi, vous indiquez à Google qu’il se trouve sur une page dont la version à indéxer est : https://www.exemple.com/blog/.
Utilisez les URL canoniques
Les URL Canoniques permettent d’indiquer qu’il existe une version privilégiée de la page actuelle pour les moteurs de recherche.
Elles renvoient un signal qui pourrait se traduire en :
« Hey les moteurs de recherche ! Je suis une page qui n’a pas de vocation SEO, utilisez plutôt cette page pour votre index ! »
Voici à quoi elles ressemblent :
<link rel="canonical" href="https://www.exemple.com/blog/">En règle général, il est considéré comme une bonne pratique de toujours mettre une URL canonique sur une page.
Ainsi, si votre CMS fait n’importe quoi (comme WordPress), les pages « invisibles » générées auront cette URL canonique et ça limitera la casse.
Faites des redirections 301
Si vous avez des pages dupliquées et que vous voulez tout simplement vous en débarrasser, il est souvent plus simple de faire des redirections vers la page à indéxer.
Les redirections 301 sont souvent plus faciles à mettre en place et vous permettent de conserver les acquisitions de ces pages (comme les backlinks si votre site est ancien).
Par défaut, je recommande de rediriger systématiquement les URL en HTTP://* vers leur version HTTPS://*.
Vous devriez également rediriger les URL avec et sans trailing slash (le / à la fin de l’URL) vers la version que vous choisissez.
Ce sont les deux plus grosses causes de problème, et, même si elles sont complètement gérées par les moteurs de recherche, ce sont des choses qui peuvent être pénibles pour plein d’autres raisons.
Utiliser noindex sur les taxonomies et les pages de recherche
Les taxonomies sont les « catégories » (ou tout ce qui peut s’en rapprocher).
Elles ont un gros intérêt pour les utilisateurs parce qu’elles permettent de filtrer le contenu afin de le retrouver plus rapidement.
Mais…
Elles sont également une énorme source de contenu dupliqué.
Il n’y a pas d’intérêt particulier à afficher ces pages dans l’index de Google. Personne ne va taper « Votre Entreprise Blog CatégorieA » en espérant tomber sur votre page.
Plutôt que de créer de la confusion pour les moteurs de recherche, ajouter une balise noindex dans l’entête de votre document HTML afin de vous en débarrasser.
C’est également le cas pour les pages de recherche.
Il est récurrent de trouver des pages /search sur certains sites internet. Comme pour les taxonomies, ce sont des pages très utiles, mais elles n’ont pas d’intérêt à être indexées.
Utiliser un fichier robots.txt
Le fichier robots.txt est un fichier qui permet de bloquer le crawling vers certaines pages de votre site internet.
Si vous avez du contenu dupliqué sur des pages que vous ne pouvez pas contrôler, et que vous ne voulez pas voir indéxer, vous pouvez l’utiliser pour bloquer l’accès à ces URLs.
D’ailleurs, vous aurez sans doute souvent des problèmes de contenu dupliqué avec des fichiers PDF (ou équivalents), et le robots.txt est le meilleur moyen de bloquer l’accès vers ces fichiers.
Et… Ne rien faire
On l’a déjà répété plusieurs fois, mais parfois, le contenu dupliqué est une bonne chose pour les utilisateurs.
Si vous souhaitez conserver des pages avec du contenu dupliqué, ce n’est pas grave.
Google choisira de toute façon quelle page affichée et dans quel contexte.
Par exemple, votre page d’accueil ne cessera pas d’être affichée pour les gens qui recherchent votre nom de marque parce qu’elle présente vos 15 derniers articles de blog.
De même, vos articles de blogs ne seront pas filtrés des résultats lorsqu’un internaute tapera les mots clés auxquels elle répond.
À partir du moment où vous avez optimisé les points ci-dessus, et qu’aucun de ces cas ne s’applique à votre situation, ne vous prenez pas la tête.
Les moteurs de recherche sont suffisamment intelligents pour gérer la situation seuls, et ça ne vous causera aucun problème.
Conclusion
Contrairement à ce que les légendes peuvent en dire, le contenu dupliqué ne conduit pas à des pénalités venant des moteurs de recherche.
Cela dit, il est possible que ces derniers aient des difficultés à interpréter vos différents contenus similaires.
Ainsi, lorsque vous le pourrez, faites le maximum pour leur faciliter la tâche.
Non seulement vous assurerez les résultats que vous espérez, mais en plus, vous optimiserez votre crawl budget et votre contrôle sur les pages de votre site internet.
Pour ce faire, vous pouvez utiliser différentes techniques : noindex, redirections 301, etc.
Chaque situation dispose en général d’une solution adaptée.