Le robots.txt est un fichier texte qui permet aux sites internet de donner des consignes aux moteurs de recherches qui viendraient analyser leurs pages.
En réalité, au-delà des moteurs de recherche, ce fichier donne des consignes à tous les robots qui pourraient crawler votre site.
Que ce soit Google, Bing, Qwant, ou n’importe quel moteur de recherche, il respectera ce que vous indiquerez dans ce fichier.
C’est ainsi un excellent moyen d’optimiser votre crawl budget.
Sommaire
Pourquoi c’est important de le mettre en place ?
Le fichier robots.txt n’est pas obligatoire et il n’y a pas de pénalité à ne pas en avoir.
D’ailleurs, ce fichier n’est pas nécessaire pour tous les sites internet. Google sera capable de trouver et indexer toutes les pages importantes de votre site internet sans prendre d’instruction de votre part.
Et dans l’autre sens, il prendra également la liberté de ne PAS indexer les pages sans intérêt ou avec du contenu dupliqué.
Pourtant, il permet certaines choses :
- Optimiser le crawl budget. Si vos pages mettent du temps à s’indexer (voir, ne s’indexe pas du tout), c’est sans doute parce que Google passe plus de temps à visiter des pages sans intérêt qu’à visiter les pages que vous voulez indexer. Le robots.txt permet de corriger ce problème en bloquant l’exploration des pages sans intérêt.
- Bloquer l’accès aux pages non publiques : Par exemple, vous pourriez avoir des pages que vous ne voulez pas indexer : des pages de connexion, la page « panier » d’un site e-commerce », etc.
Les exemples ne manquent pas. Ces pages doivent exister, mais elles n’ont pas vocation à être sur les moteurs de recherche. Le robots.txt permet de bloquer l’accès à ces pages. - Empêcher l’indexation des ressources. Google voudra indexer des fichiers présents sur votre site internet, par exemple, des fichiers PDF ou des images. Si vous ne voulez surtout pas partager ces éléments sur le web, vous devrez utiliser le fichier robots.txt pour en bloquer l’accès.
Globalement, ce fichier permet d’empêcher les robots de visiter certaines pages de votre site internet.
Fonctionnement du robots.txt
Le fichier robots.txt contient des instructions. Ces instructions sont respectées à la lettre par les moteurs de recherche et vous permet ainsi de leur indiquer des URL (ou groupe d’URL) à ne pas visiter, ou ne pas indexer.
Non seulement vous pouvez donner des consignes AUX robots, mais vous pouvez également donner des instructions différentes à chacun d’entre eux.
Par exemple, vous pourriez interdire l’accès aux robots qui ne vous intéressent pas. C’est d’ailleurs ce que nous avons fait sur notre robots.txt.
Si vous ne bénéficiez pas du crawling de certains robots en particulier, je vous recommande de les désactiver.
À part consommer des ressources inutilement, vous n’en gagnerez aucun bénéfice.
Une fois que vous aurez créé votre fichier, vous devrez le servir à l’URL suivante afin qu’il soit identifiable par les moteurs de recherche : https://www.exemple.com/robots.txt
Les directives de base
Il existe une convention à respecter pour les fichiers robots.txt. Celle-ci permet aux algorithmes de comprendre plus facilement vos directives.
Voici les principaux éléments.
User-agent: {nom_du_robot}.
Cette directive permet de sélectionner un robot en particulier, par exemple User-agent: Googlebot indique que les directives suivantes (et ce, jusqu’à la prochaine directive User-agent) concerneront Googlebot uniquement.
Vous pouvez sélectionner tous les robots en utilisant une « wildcard » (il s’agit de l’astérisque : *). Par exemple : User-agent: * va sélectionne tous les robots.
De même, vous pourriez vouloir utiliser une wildcard pour donner des règles à tous les robots, puis, en exclure une liste. Dans ce cas, vous utiliserez une nouvelle directive User-agent après celle de la wildcard, comme dans cet exemple :
# Global rules
# -----------------
User-agent: *
Disallow: /blablabla/
# Ban bots that don't benefit us.
# --------------------------------
User-agent: Nuclei
User-agent: magpie-crawler
Disallow: /Dans cet exemple, tous les robots peuvent crawler votre site internet (à l’exception du répertoire www.exemple.com/blablabla/ et toutes les sous pages qu’il contient) sauf les robots Nuclei & magpie-crawler qui ne peuvent pas accéder à votre site internet.
Sitemap : {url}
Cette directive permet d’indiquer l’URL de votre (ou vos) sitemap.
Cette directive est assez importante, placez-y votre sitemap dès qu’il sera mis en place. Également, placez-y plutôt l’index de vos sitemaps plutôt que de les indiquer un par un.
Les deux options sont valables, mais avec l’index, vous serez sûr de ne pas en oublier un s’ils sont générés dynamiquement.
Disallow: {url} et Allow: {url}
Ces directives permettent de bloquer ou d’autoriser l’accès à des URL spécifiques ou à des listes d’URL.
Par défaut, toutes vos URLs sont en Allow, vous n’avez donc pas besoin de le préciser. Cette directive ne sert qu’à surclasser des règles Disallow antérieures.
Par exemple si on reviens à l’exemple antérieur :
# Global rules
# -----------------
User-agent: *
Disallow: /blablabla/
# Ban bots that don't benefit us.
# --------------------------------
User-agent: Nuclei
User-agent: magpie-crawler
Allow: /blablabla/Dans ce cas, tous les robots ne peuvent pas visiter le répertoire /blablabla/, à l’exception de Nuclei et magpie-crawler.
Pourquoi ? Parce que Allow vient APRÈS la règle Disallow. Les règles sont interprétées dans l’ordre du fichier.
Disallow, vous l’aurez compris, permet de bloquer l’accès à des pages. Pour bloquer une URL spécifiquement, vous devrez indiquer l’URL absolue (avec https://www.exemple.com/ avant le répertoire).
Bien sûr, souvent vous voudrez bloquer un ensemble de pages, pas spécifiquement une URL en particulier.
Et vous n’avez pas envie de copier-coller 1000 URLs pour en bloquer l’accès.
Pour cela, vous pouvez également utiliser les wildcards.
Dans le cas de ces deux directives, il en existe une deuxième, on l’a vue dans le premier exemple, il s’agit du /.
Inscrire Disallow: / indique que vous voulez bloquer l’accès à l’ensemble de votre site.
Si vous voulez par contre bloquer l’accès à tous vos fichiers PDF, vous allez utiliser l’astérisque et le dollar :
Disallow: /*.pdf$
Dans ce cas, vous indiquez que vous voulez bloquer toutes les URLs qui se terminent par .pdf (donc tous les fichiers PDF de votre site.
Les commentaires
Il est possible d’écrire des commentaires dans un fichier robots.txt.
Bien sûr, les crawler vont complètement ignorer ces indications, cependant, les fichiers robots.txt sont souvent utilisés par de vrais humains (des experts SEO par exemple).
C’est souvent un bon endroit où placer une offre d’emploi SEO si vous recherchez activement quelqu’un.
À l’inverse, si vous cherchez un emploi en SEO, vous pouvez rechercher des adresses email dans ce fichier.
Pour écrire un commentaire, il vous suffit de commencer votre ligne par le symbole : #
Tester son fichier robots.txt
Avoir un fichier bien configuré est très important, une erreur pourrait conduire à une « désindexation » totale de votre site internet.
Vous devez donc vous assurer qu’il est correct avant de le publier sur votre site internet.
Une fois que vous avez écrit votre fichier, vous pouvez le tester avec l’outil pour webmaster mis à disposition par Google.

Si votre fichier n’a pas de problème vous devriez voir ceci en bas à gauche. Dans ce cas là, c’est tout bon, vous pouvez publier votre fichier.
Robots.txt vs Meta
C’est bien joli tout ça, mais je peux déjà le faire avec les meta noindex non ?
C’est vrai, vous pouvez empêcher les moteurs de recherche d’indexer des pages en plaçant la balise suivante dans l’entête de votre fichier HTML :
<meta name="robots" content="noindex, nofollow">Toutes les pages qui disposent de cette balise se verront désindexer par les moteurs de recherche.
Seulement, il y a plusieurs problèmes à se contenter de ces éléments :
- En premier lieu, vous ne pouvez pas appliquer cette balise à toutes les pages, par exemple les fichiers image, pdf, etc. C’est également parfois plus compliqué de modifier cette balise que de créer un fichier robots.txt.
- En second lieu, vous bloquez l’indexation, certes, mais pas le crawling de ces pages. Avec le fichier robots.txt, Googlebot ne visitera pas vos pages, et, vous préserverez votre CrawlBudget.
- Enfin, ce fichier permet d’indiquer l’URL de votre sitemap.xml, et de faciliter son accès aux moteurs de recherche.
Maintenant, comme je l’ai dis dans l’introduction, ce fichier n’est pas obligatoire. Vous ne risquez aucune pénalité à ne pas le mettre en place.
Mise en place du robots.txt pour WordPress
Comme l’écrasante majorité d’entre vous utilise sans doute WordPress, faisons la mise en place d’un fichier robots.txt sur ce CMS.
La manière la plus simple de mettre en place ce fichier, c’est d’utiliser un plugin de SEO comme Yoast SEO.
Une fois ce plugin installé, vous pourrez vous rendre sur l’URL : https://www.votresite.com/wp-admin/admin.php?page=wpseo_tools
Vous devriez tomber sur cette page :
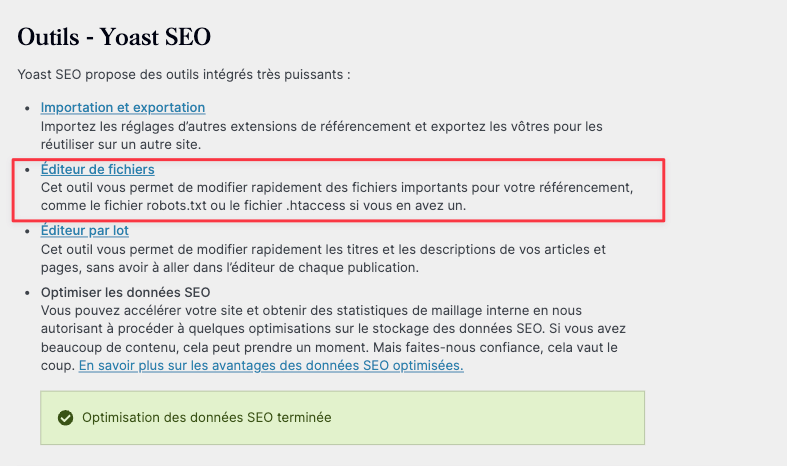
Petit aparté ici.
Il est possible que le contenu de l’encadré rouge ne s’affiche pas de votre côté.
C’est « normal ». C’est une mesure de sécurité qui empêche les plugins de modifier les fichiers de votre application.
Pour lever cette sécurité, ajoutez cette ligne de cote à la fin de votre fichier wp-config.php :
<?php
// contenu de wp-config.php
define('WP_DEBUG_DISPLAY', true);Ensuite, vous devriez tomber sur la page en question, et, en cliquant sur « Éditeur de fichiers », vous devriez arriver sur cette page :
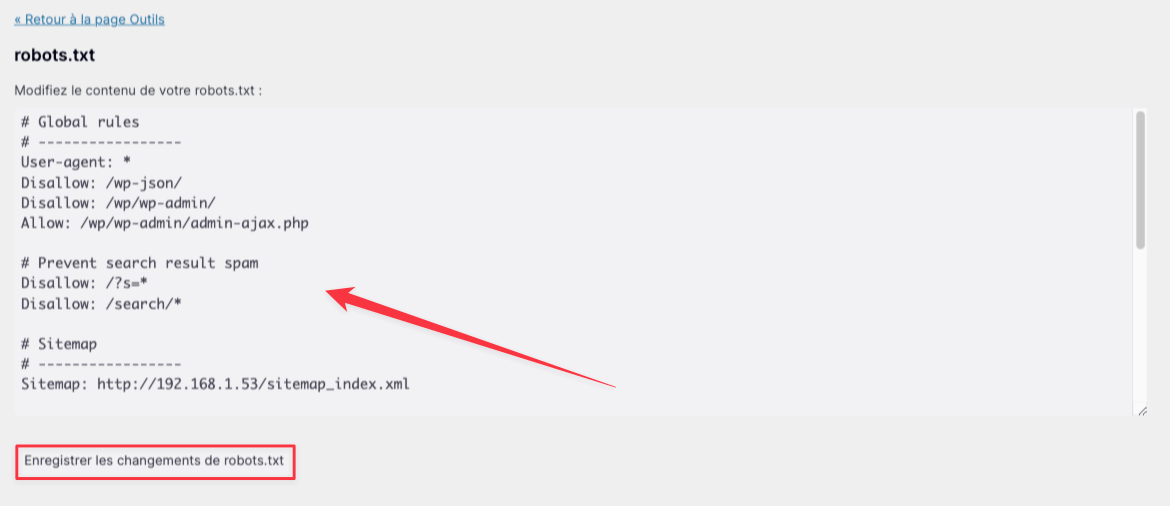
Le contenu recommandé
Le contenu de ce fichier n’est pas évident à déterminer, en particulier si vous ne connaissez pas parfaitement WordPress et tous les pièges qu’il inclut.
Nous recommandons d’utiliser ce fichier, qui est une version inspirée de celui recommandé par Yoast SEO :
# Global rules
# -----------------
User-agent: *
Disallow: /wp-json/
Disallow: /wp-admin/
Disallow: /wp-login/
Disallow: /wp-cron/
# Bedrock support
Disallow: /wp/wp-admin/
Disallow: /wp/wp-login/
Disallow: /wp/wp-cron/
# Block search results search
Disallow: /?s=*
Disallow: /search/*
# Sitemap
# -----------------
Sitemap: https://www.votresite.com/sitemap_index.xml
# Ban bots that don't benefit us.
# --------------------------------
User-agent: Nuclei
User-agent: WikiDo
User-agent: Riddler
User-agent: PetalBot
User-agent: Zoominfobot
User-agent: Go-http-client
User-agent: Node/simplecrawler
User-agent: CazoodleBot
User-agent: dotbot/1.0
User-agent: Gigabot
User-agent: Barkrowler
User-agent: BLEXBot
User-agent: magpie-crawler
Disallow: /Sans rentrer trop dans les détails, ce fichier permet de bloquer les pages qui, dans toutes les instances possibles de WordPress, peuvent poser problème.
Bien sûr, vous pourrez (et souvent, vous devrez) ajouter les règles spécifiques à VOTRE site internet.
Conclusion
Le fichier robots.txt est un fichier texte placé à la racine de votre serveur web qui permet de donner des directives de crawl aux moteurs de recherche, et, plus globalement, à tous les robots qui voudraient crawler votre site.
Ce fichier n’est pas obligatoire, mais il est très intéressant parce qu’il permet d’optimiser votre Crawl Budget, de préserver des fichiers ou pages de l’indexation, ou encore, d’interdire l’accès à des spiders qui ne vous intéressent pas.
C’est un fichier très simple à mettre en place et qui répond à des conventions précises.
Vous pouvez tester la validité de votre fichier robots.txt à l’aide des outils mis à disposition par Google ou Bing.
Sur WordPress, vous pouvez utiliser Yoast SEO pour mettre en place votre fichier facilement.