Le Crawl Budget c’est le nombre de pages que Googlebot peut parcourir et indexer pour un site internet donné, et pour un interval de temps donné.
C’est une métrique qui varie d’un site internet à un autre et qui dépend de plusieurs facteurs comme la performance de votre site, la taille de vos contenus ou encore la difficulté d’accès à vos pages.
Il est souvent recommandé de mettre en place un Sitemap XML dans le but d’optimiser son Crawl Budget et c’est une recommandation que nous faisons également !
Sommaire
Pourquoi le Crawl Budget est un facteur important en SEO ?
La théorie à ce sujet est assez simple.
Si Google n’indexe pas vos pages, elles ne sont visibles sur aucun résultat de recherche.
Or, on vient de le voir, le Crawl Budget définit la capacité pour le moteur de recherche à explorer vos pages et à les classer.
Cette capacité est limitée pour un interval de temps donné, et donc, si vous dépassez la limite, vos pages risquent de ne pas être indexées avant longtemps.
Pour faire simple, si vous avez un nombre de pages qui dépasse le budget alloué à votre site internet par Google Boy, vous allez avoir des pages qui ne seront pas indexées.
Pourquoi existe t-il une limite ?
Visiter un site internet et rechercher de nouvelles pages, ça prend du temps pour un robot d’exploration.
Qui dit temps en informatique dit coûts.
Et oui, si Google passe plusieurs minutes chaque jour pour chaque site internet dans le monde, il lui faut des ressources de calcul très importantes pour réussir sa mission.
Le Crawl Budget a été inventé dans cette optique.
En limitant les passages des robots et la durée des explorations, Google incite les webmasters à optimiser ce phénomène afin de lui permettre de prioriser l’exploration des contenus à forte valeur et le plus facilement possible.
Et si vous ne le faites pas …
Et bien ce n’est plus son problème.
Vous devrez patienter plus de temps pour voir votre contenu indexé, tout le monde est logé à la même enseigne et Google n’allouera pas un budget supplémentaire juste pour vous.
Le Crawl Budget permet donc de standardiser les explorations des sites internet et de limiter les ressources dépensées pour explorer et indexer de nouveaux contenus.
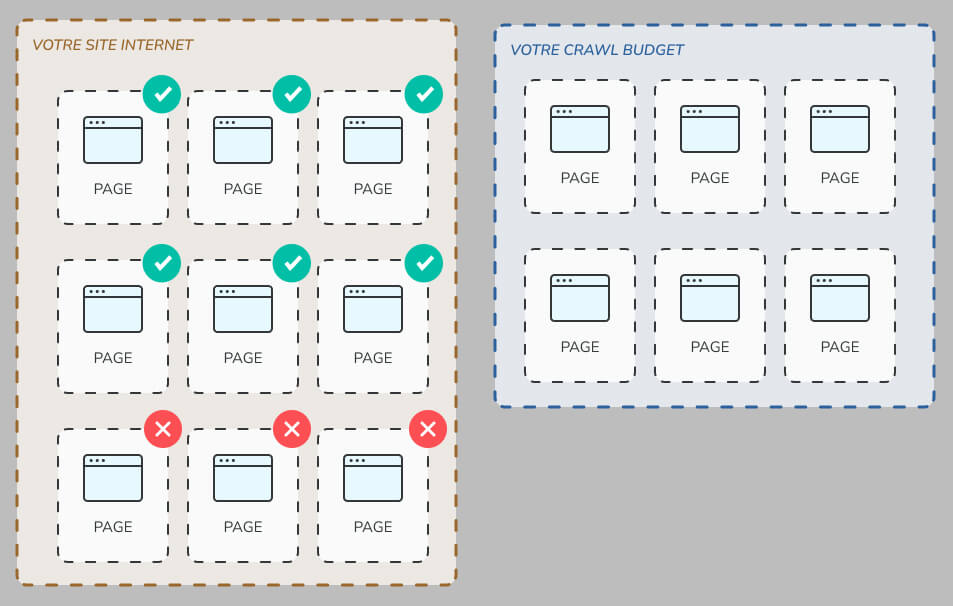
Comme vous le voyez dans ce schéma, si Googlebot vous a alloué 6 pages pour son exploration, mais que vous avez ajouté 9 pages sur votre site, 3 de ces pages devront attendre la prochaine exploration de Googlebot.
Bien sûr, si vous rajoutez encore 9 pages au passage suivantes, vous aurez alors 6 pages qui verront leur indexation retardée, et ainsi de suite !
Comme vous pouvez le voir, le Crawl Budget peut avoir de sérieuses répercussions sur vos efforts de publication.
Qui est concerné par le Crawl Budget ?
Google est vraiment très performant quand il s’agit de découvrir de nouveaux contenus et de les indexer.
Après tout, il n’est pas de très loin le meilleur moteur de recherche au monde pour rien.
Donc, pas de panique, le Crawl Budget n’est en réalité pas un problème pour la plupart des sites web.
En réalité, il concerne surtout les cas suivants :
- Vous avez mis en place BEAUCOUP de redirections (301, 302, etc.). Chaque redirection est considérée comme une page à part entière alors … Évitez les redirections inutiles.
- Vous venez d’ajouter beaucoup de pages d’un coup (par exemple, vous venez de traduire tout votre site internet d’un seul coup).
- Vous managez un site internet très gros qui publie des milliers de pages par jour (un site d’annonce par exemple).
- Vos pages sont très souvent mises à jours.
Dans ces cas là, vous allez chercher à optimiser votre Crawl Budget dans l’optique d’être le plus efficace à chaque passage des robots d’exploration.
Optimiser son Crawl Budget
On l’a dit, c’est le coût en ressource qui impose aux moteurs de recherche de limiter l’exploration de votre site.
Si on garde ça dans un coin de sa tête, il est logique de penser que, limiter le coût pour chaque page visitée permet d’augmenter le nombre total de pages explorées à chaque passage.
Et…
C’est exactement ce que vous devez faire !
Optimiser les performances du site internet
Plus vos pages répondront rapidement, moins de temps vous bloquerez l’exploration de Googlebot.
En fait, Google l’a déjà annoncé publiquement :
« Améliorer la vitesse de votre site internet non seulement améliore l’expérience de vos utilisateurs, mais elle améliore aussi le nombre de pages crawlées. »
En gros : Plus votre site est lent, moins Googlebot pourra en explorer.
Dramatique n’est-ce pas ?
Voici par exemple le temps de chargement d’un site internet pris au hasard sur un profil Linkedin :
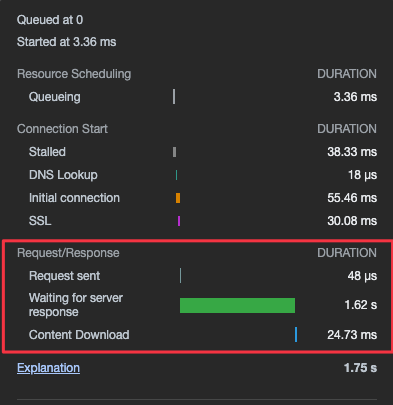
Comme vous pouvez le voir, chaque visite faite sur ce site internet bloque GoogleBot pendant 1,75s.
1,62s sur ce temps total est monopolisée par le serveur web qui met trop de temps à rendre la page demandée.
En guise de comparaison, voici un des derniers sites que nous avons mis en ligne avec Olympe Studio :
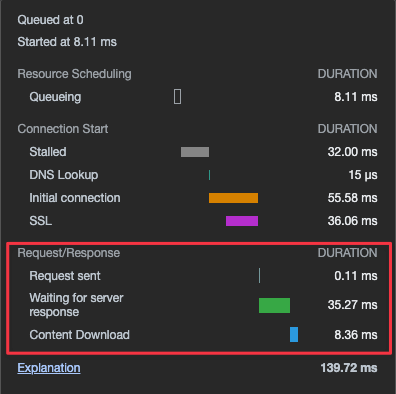
Sur ce site, une requête bloque le robot d’exploration pendant 0,14s. C’est 800 fois moins de temps que le site du premier exemple.
Dans le deuxième exemple, Googlebot a 800 fois plus de temps (pour chaque page visitée) pour explorer les URLs de votre site, et cela seulement parce que le site internet est super performant.
Réduire le ratio Texte/HTML de vos pages
Si nous reprenons l’exemple précédent, vous pouvez remarquer un autre élément important.
La durée du téléchargement pour les deux pages est 3x plus rapide dans notre cas que dans celui du site internet sélectionné au hasard.
Le poids d’une page HTML est souvent significatif d’un ratio HTML/Texte assez mauvais.
Plus une page aura un balisage HTML mal formaté, plus il sera long pour les robots d’analyse de comprendre votre contenu. (en plus d’être plus long à télécharger)
Améliorer votre HTML est une bonne pratique pour optimiser le Crawl Budget de votre site. Pour cela vous pouvez suivre les recommandations suivantes :
- Utiliser des fichiers à part pour le Javascript et le CSS,
- N’utilisez pas de Builder de page (Elementor, webflow, etc.) Ils produisent du marquage de mauvaise qualité pour répondre à des contraintes techniques,
- Utilisez du CSS moderne pour éviter d’avoir recours à des nœuds supplémentaires pour styliser vos éléments,
- Optimisez vos pages avec postCSS pour renommer et réduire la taille de vos classes CSS dans le rendu final.
Le maillage interne
Le maillage interne est également un facteur très important parce qu’il permet à Googlebot de découvrir de nouvelles pages plus facilement via les liens que vous faites entre vos contenus.
Google met la priorité sur les pages qui ont beaucoup de liens internes et externes qui pointent vers elles.
Internes ET externes.
Dans un monde idéal, vous voudriez avoir des liens externes qui pointent vers chacune de vos pages, mais c’est rarement le cas dans le monde réel.
Heureusement, les liens internes vont vous aider à rediriger les robots vers d’autres contenus.
Imaginons un instant que site A pointer vers l’une de vos pages qui pointe elle même vers les pages B, C et D.
Inutile que site A ou un autre site pointe vers les pages B, C ou D pour que Googlebot tombe dessus. Le lien de site A vers page A est suffisant parce que Googlebot suit les liens sur une page.
Super cool n’est-ce pas ?
Mettre en place des cocons sémantiques sur votre site internet est une bonne manière d’utiliser ce comportement à votre avantage.
En plus ça aura un impact significatif sur le classement de vos pages grâce à la transmission du jus de lien.
Double bénéfice !
Pensez également à chercher et corriger les liens brisés. (ce sont les liens qui pointent vers une URL qui renvoie un status 404).
Une arborescence simple
Les URLs qui sont les plus populaires sur internet sont celles qui sont le plus re-explorée par Google.
Et c’est logique. Google veut mettre à jour le contenu qui plait.
Dans ce processus, Google transmet de l’autorité à ces pages.
Et …
Ces pages les transmettent aux pages auxquelles elles font référence dans leur contenu.
C’est pour cette raison que vous voulez une arborescence simple, où toutes les pages de votre site sont accessible de n’importe quelle autre page en moins de 3 clics.
3 clics c’est peu, mais c’est en réalité assez simple à mettre en place.
Par dessus tout, évitez les pages orphelines, perdue dans un espace difficile d’accès de votre site.
Voici l’arborescence à privilégier :
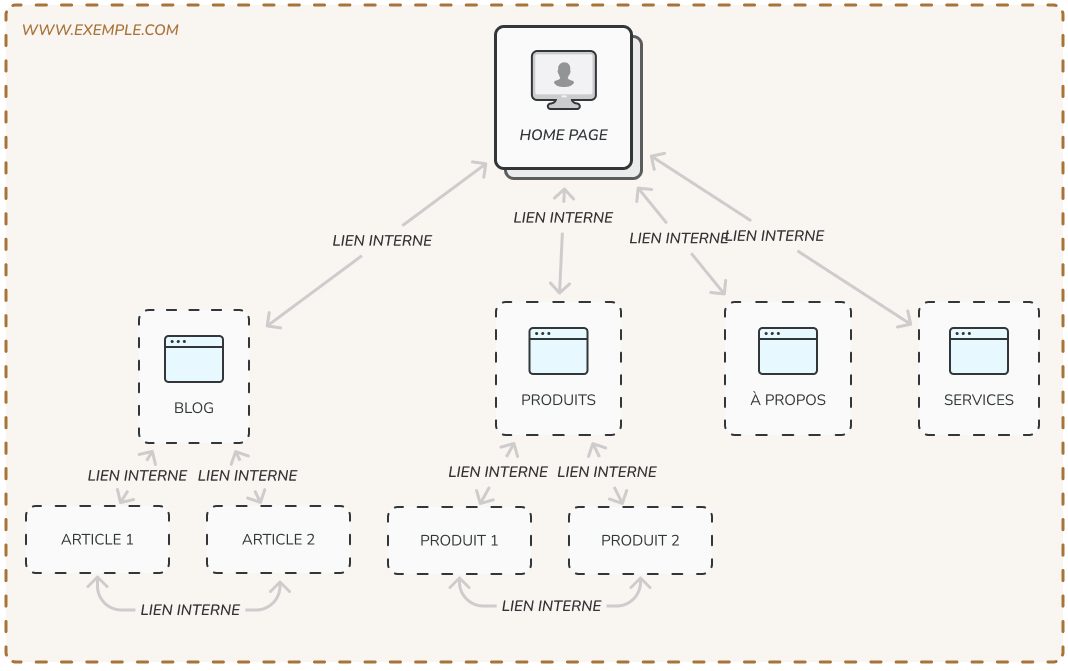
Pour un moteur de recherche, une page orpheline est très difficile à découvrir. Évitez-les à tout prix.
Évitez le contenu dupliqué
Il existe plein de raison d’éviter le contenu dupliqué, et c’est en général une très mauvaise chose pour le référencement naturel.
Le Crawl Budget est une de ces raisons : Google ne veut pas gaspiller des ressources pour indexer des pages dont le contenu est déjà disponible sur d’autres pages.
Et, c’est encore pire si ce contenu est dupliqué d’un autre site que le vôtre.
Faites en sorte de toujours proposer du contenu de qualité, unique et facile d’accès.
Vous pouvez également utiliser le fichier robots.txt pour indiquer à Googlebot que vous ne voulez pas gaspiller son budget sur certaines pages. Il suivra vos recommandations en ne les explorant pas.
Utiliser un Sitemap
On en a parlé dans l’introduction, mais l’utilisation d’un sitemap XML permet à Googlebot de détecter beaucoup plus rapidement vos nouvelles pages.
C’est également un fichier qui indique les pages mises à jour et qui est très économe en ressources.
C’est un élément basique, mais il permet d’améliorer grandement la découvrabilité de vos pages, en particulier sur un site immense.
Pensez cependant à ne pas inclure d’URL avec des redirections ou des erreurs dans le sitemap, ainsi que des pages avec du contenu dupliqué.
Évitez également les pages que vous ne voulez pas indéxer (Balise <meta> noindex ou URL canonique différente).
Conclusion
Le Crawl Budget est une limite imposée par les moteurs de recherche dans le but d’économiser les ressources nécessaires à l’exploration des sites internet.
En dépassant cette limite, vous risquez de voir certaines de vos pages ne pas s’indexer avant un long délai.
Tous les sites internets n’ont pas de problématique de Crawl Budget, il s’agit principalement d’un problème occasionnel ou propre aux très gros sites.
Cette limite repose sur plusieurs facteurs :
- La performance de votre site,
- Le poids de vos pages,
- L’accessibilité de vos pages (sont-elles faciles à découvrir ?)
- La qualité du contenu sur vos pages,
- La popularité de vos pages en dehors de votre site (maillage externe).
En optimisant chacun de ces facteurs, vous assurerez une bonne collaboration entre votre site et Googlebot, en plus d’optimiser également la navigation de vos utilisateurs.
Travailler son Crawl Budget est donc une bonne idée, même si vous n’êtes pas directement soumis à ses contraintes.
Pourquoi ? Parce que cela peut vous permettre d’optimiser d’autres facteurs de ranking.
Et c’est pour ça qu’on se décarcasse, n’est-ce pas ?
Questions Fréquentes
Est-il possible d’augmenter son Crawl Budget ? Comment ?
Oui et non. Google a indiqué que le budget alloué à un site est ajusté en fonction de l’autorité de ses pages. L’autorité étant acquise grâce aux liens externes, ce n’est pas quelque chose de facile à mettre en place. Cela dit, c’est un travail de long terme tout à fait atteignable.
Qu’est-ce qui gaspille le plus mon budget ?
Sans aucun doute, les redirections et les liens cassés (404). Ces requêtes comptent des URL en moins tout en n’apportant aucune page à indexer. Appliquez une politique efficace pour vérifier les URL que vous placez dans vos pages et assurez-vous qu’elles sont toujours valides !
Comment éviter de Crawler des pages que je ne veux pas indexer ?
Le fichier robots.txt est spécialement conçu pour ça. Utilisez-le pour empêcher les moteurs de recherche de crawler les pages qui pourraient gaspiller votre budget. Par exemple celles qui ont une meta noindex ou une URL canonique.